Low-latency inference
Responses in milliseconds, no round-trip to the cloud.
Early 2024 — NEXA.AI had just shipped a breakthrough on-device model, then pivoted from a consumer app to a B2B platform. I joined as the sole designer, with one job: turn a raw technical achievement into a product enterprises could understand in seconds.
This wasn't a polish project. It was rapid ideation, structuring ambiguity, and shipping a product that didn't yet exist — starting from a one-sentence PRD and a two-week runway.
Final design
A complex on-device model, reframed as a hands-on Playground — built to drive trial starts, activation, and a first "oh, it really is that fast" moment.
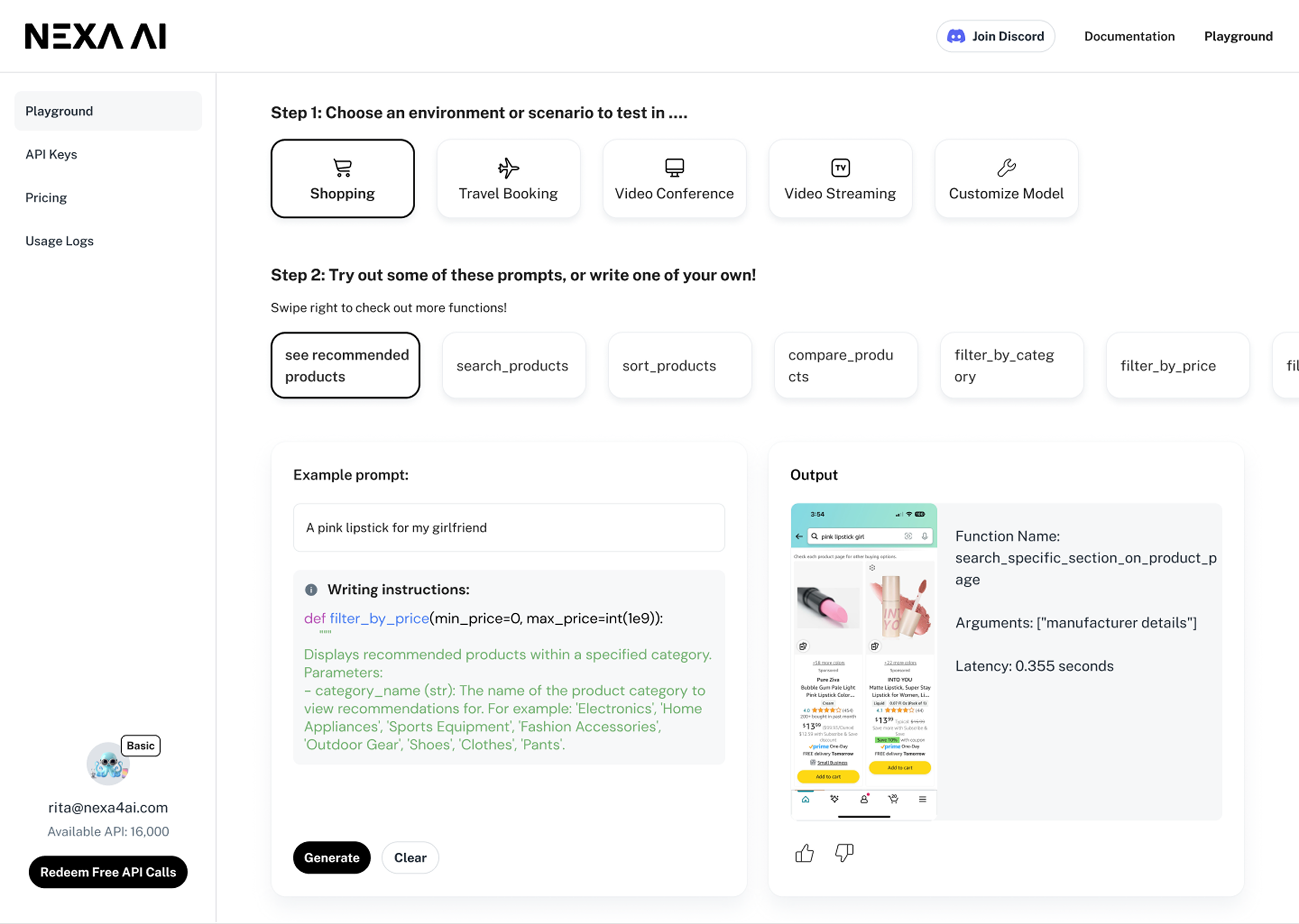
01 — Define the problem
Fast, private, truly on-device — the technical case was strong. The adoption case wasn't. Users stalled in browsing and signup, dropping off before a single inference. Without a "first successful run," speed and privacy stayed abstract.
So the real challenge wasn't adding more features. It was:
I sat with the ML team to translate early technical conversations into a product direction. Four characteristics anchored everything that followed:
Responses in milliseconds, no round-trip to the cloud.
Data never leaves the user's machine — a real story for regulated industries.
Text, image, and structured input handled by a single runtime.
Sized to deploy on laptops, phones, and embedded devices.
In parallel, I mapped how enterprises were actually adopting AI in 2024 — and where the gravity was already moving.
Rising cloud costs and hardware shortages pushed enterprises toward leaner, cheaper-to-run models.
Demand was shifting from text-only to systems that process text, image, and structured data together.
Models were getting noticeably better at understanding intent and generating natural-feeling language.
The opportunity was real — but more importantly, the model's four strengths mapped almost one-to-one onto where the market was already heading. That alignment became the north star for every design decision.
04 — User insight
3/5
interviewees said "the fastest way to understand a new model is simply to try it."
Recruited from Hugging Face & LinkedIn · engineers familiar with model evaluation
That settled the direction. Instead of bolting a chatbot onto an old flow, we'd make the experience itself the message — a focused Playground where users run the model in their first session, with minimal friction.
Two weeks, one sentence of PRD. The question I held the whole sprint: what's the simplest experience that lets the model prove itself? The answer was interaction-first — let users feel speed, privacy, and local inference inside the first minute, then layer everything else around that moment.
Not polished, not complete — built to land the value, not the brand. Four steps to a first successful run, plus the supporting surfaces enterprises actually pay through.
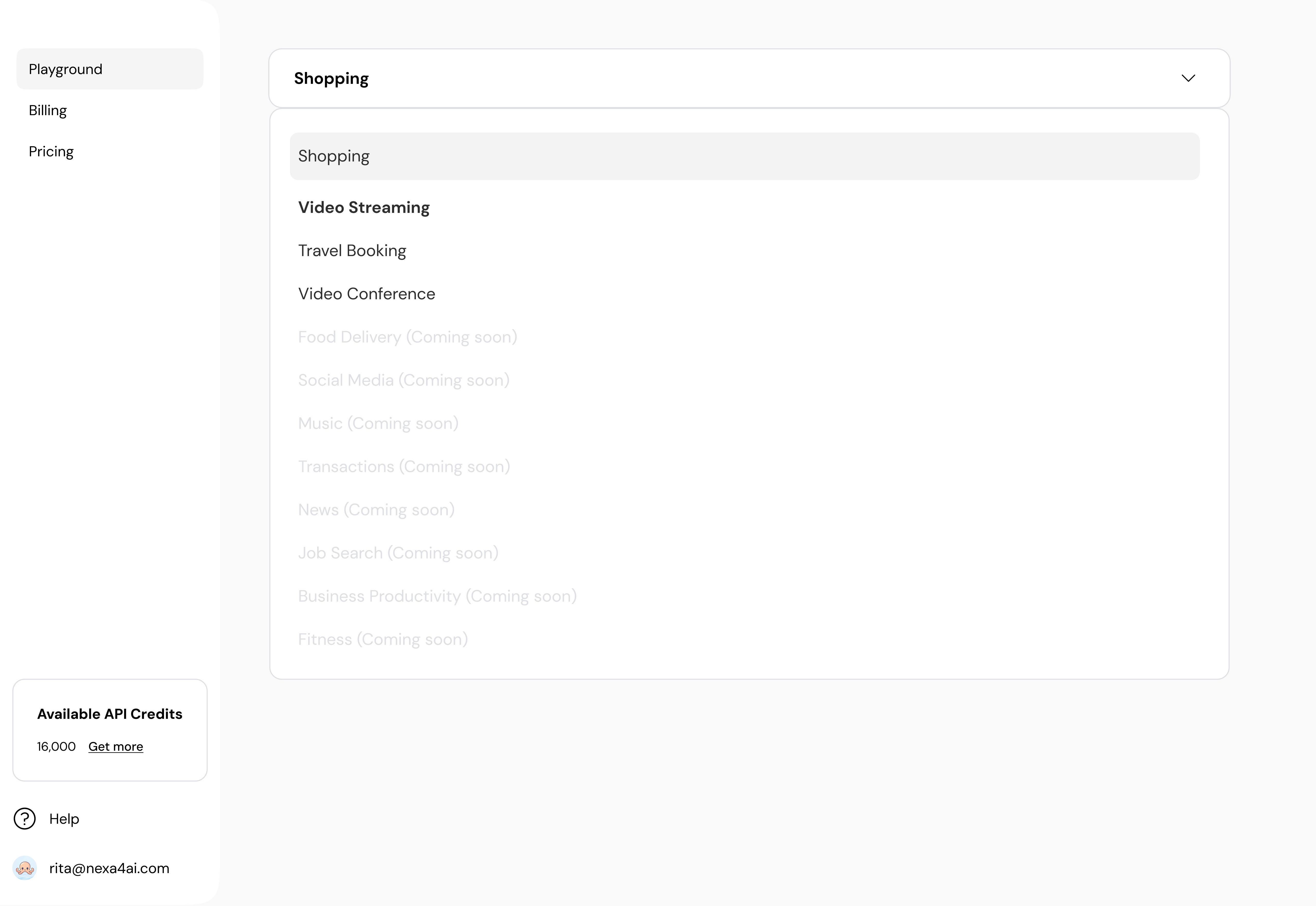
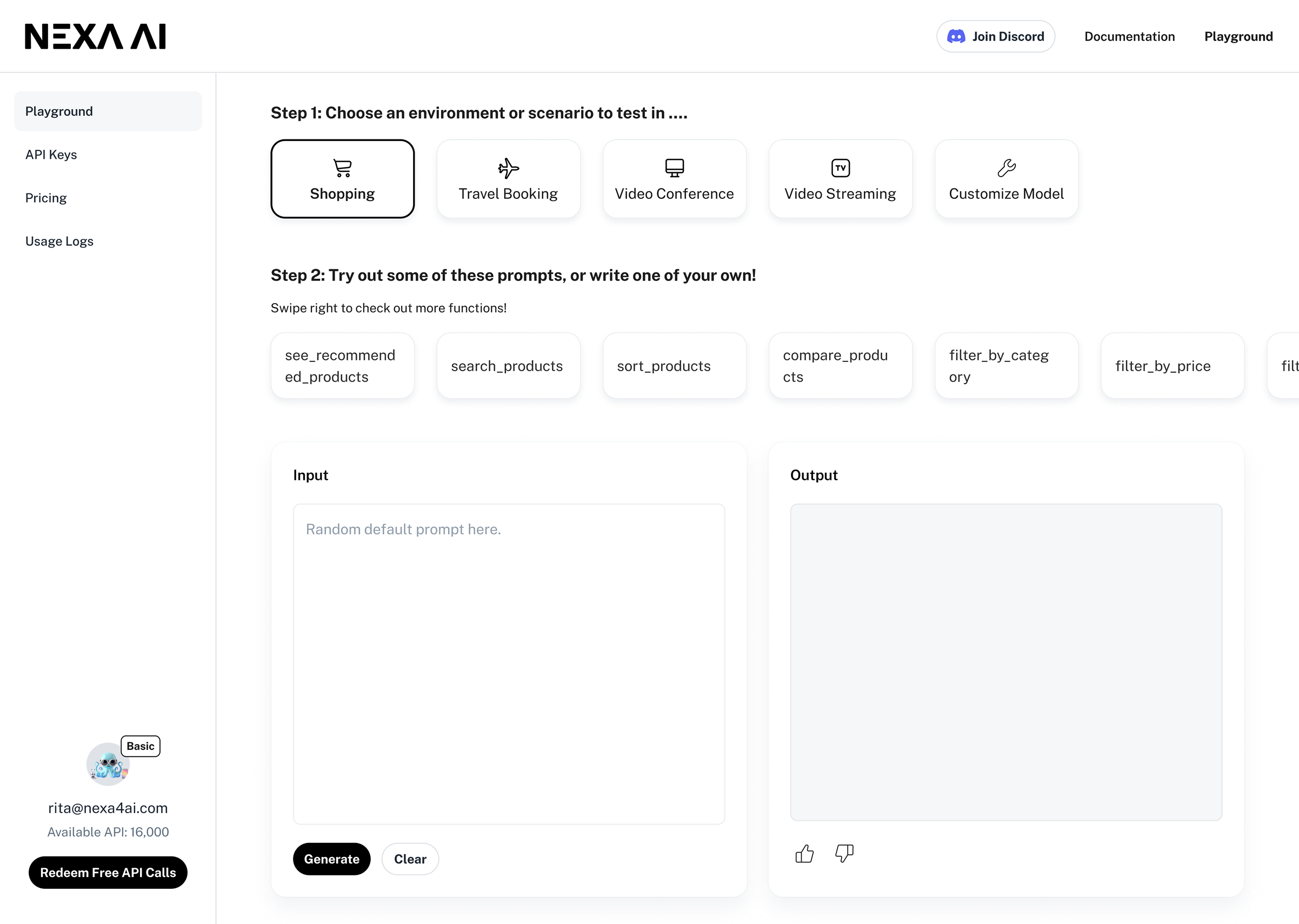
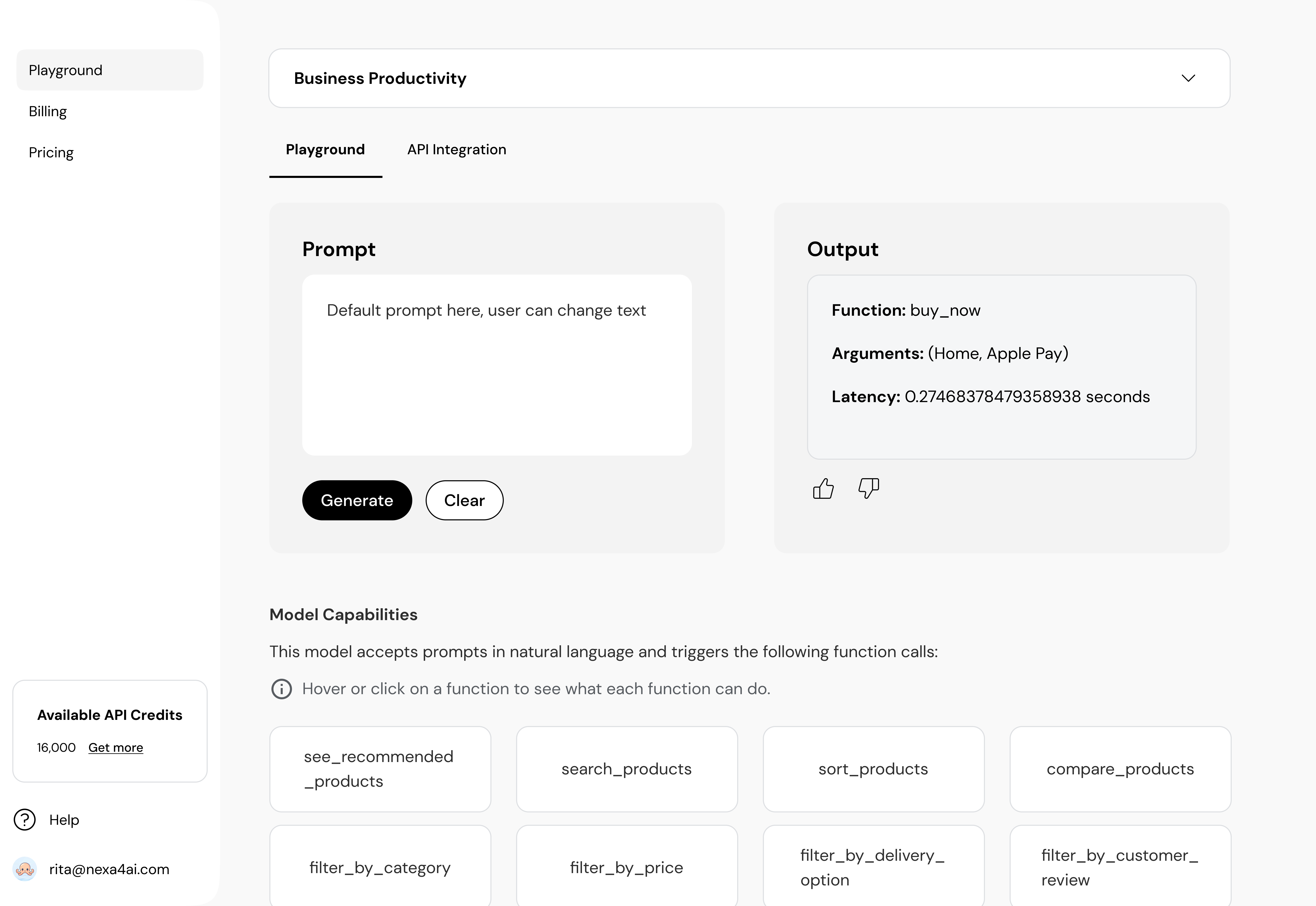
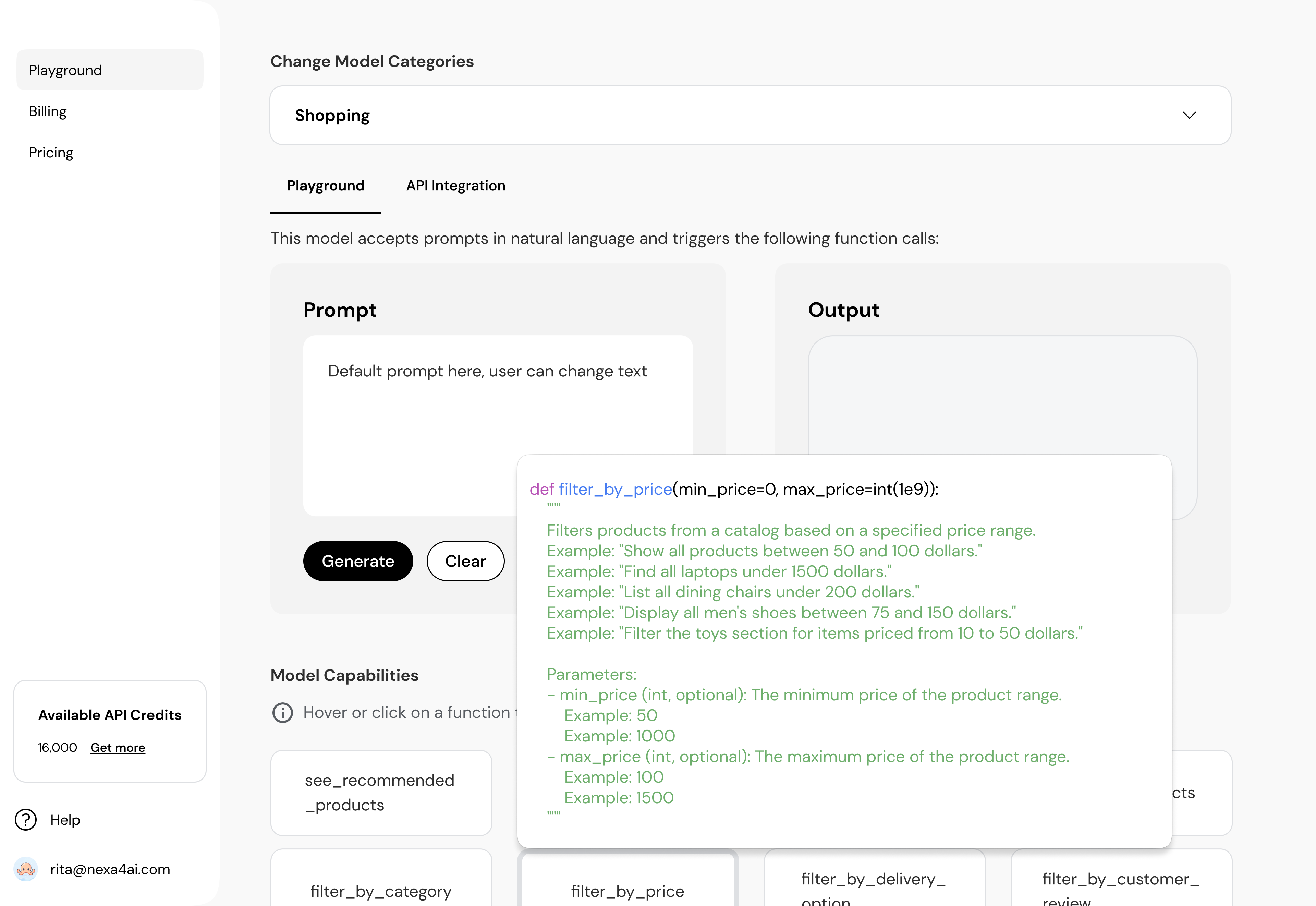

Engagement was thin. API trials were lower than we modeled. Conversion to paid — the actions that actually fund a B2B platform — barely moved. The MVP had shipped, but the value wasn't landing.
So I pulled the personas back open and split our primary audience into two — because the people stalling weren't a single user. They were non-technical buyers (marketing leads, designers, cross-functional staff) and technical evaluators (engineers, ML practitioners) reading the same page in completely different ways.
Engineers and ML practitioners. They evaluate models by running them. They want docs depth, code-level access, and a clear path from pip install to first inference — not marketing copy.
Business, marketing, and cross-functional staff exploring AI for their team. They need to understand the value without technical context. Plain language, visual demos, and industry-relevant examples land harder than docs.
Two persona tracks, two parallel design responses — each tuned to how that audience actually evaluates a new AI product.
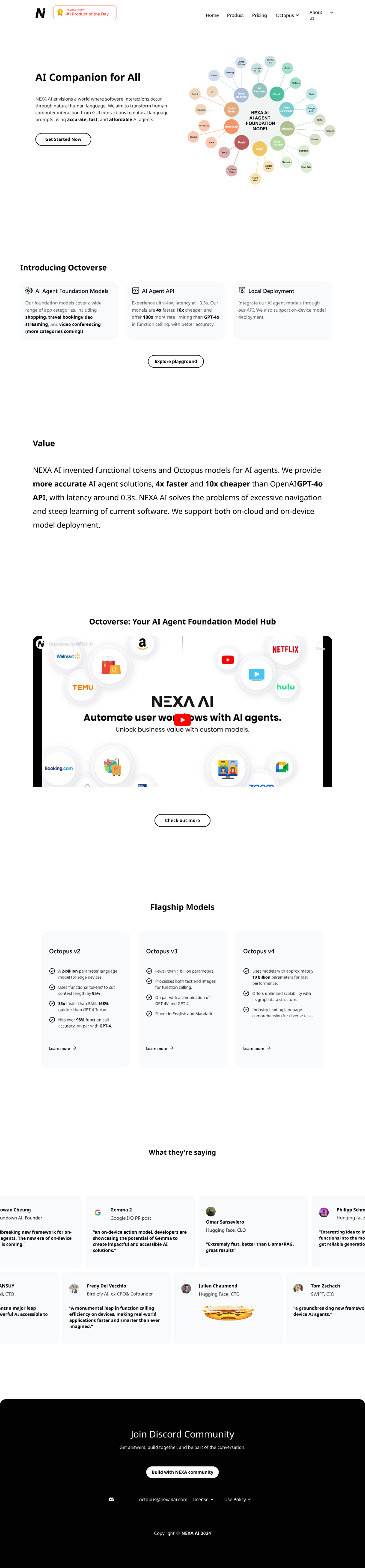
I tore down the landing page IA and rebuilt it around plain-language value, refined visual hierarchy, and a story a marketing lead could follow without reading any docs.
The landing redesign was the deliverable. The video prototypes were the story. In 2024 — before "AI agent" became a category — I picked four industries already brushing up against on-device intelligence and storyboarded what a user's day could look like when the model is simply there: anticipating intent, acting on context, working ahead of the prompt. These ended up being the most-cited artifact in our enterprise conversations.
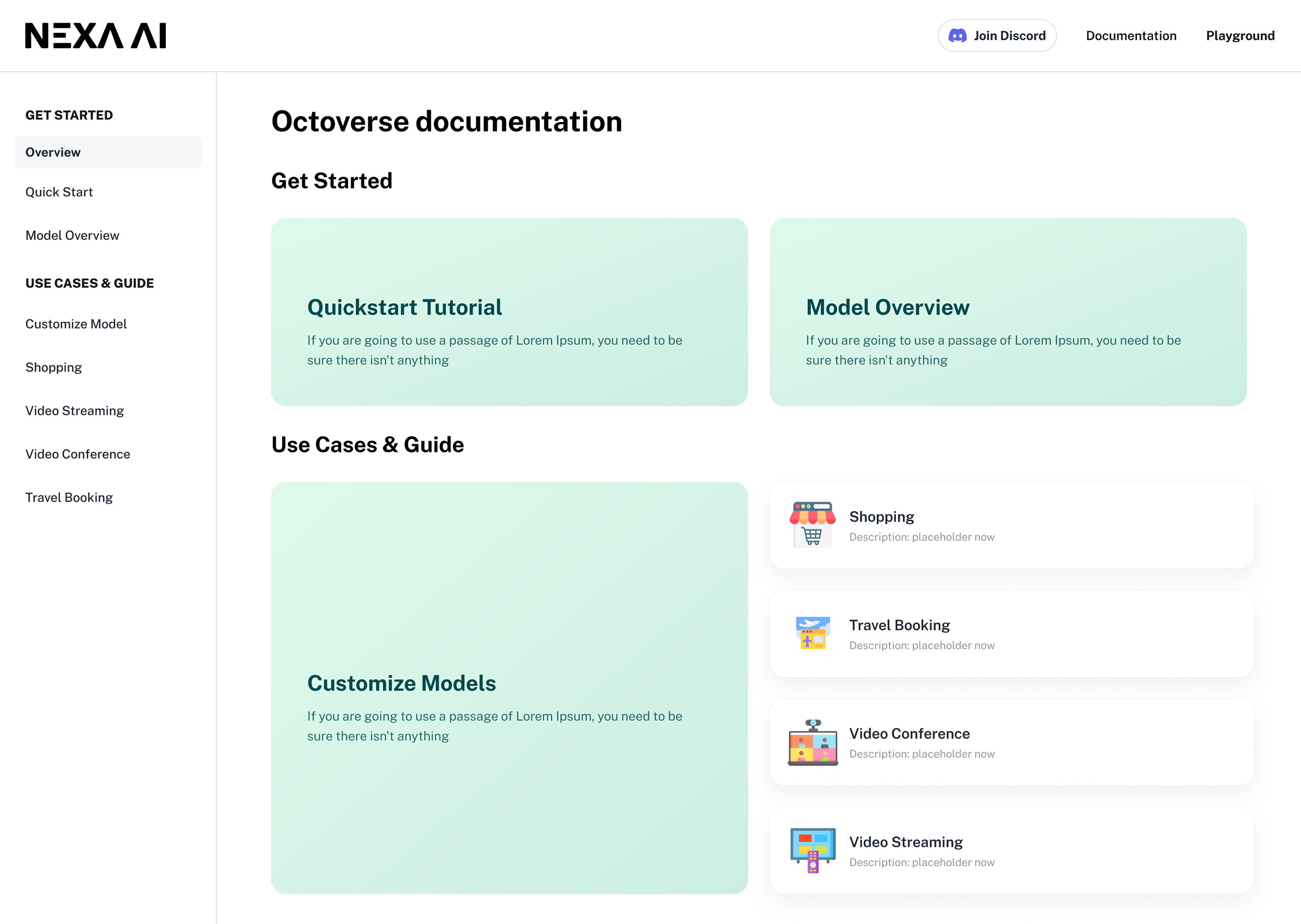
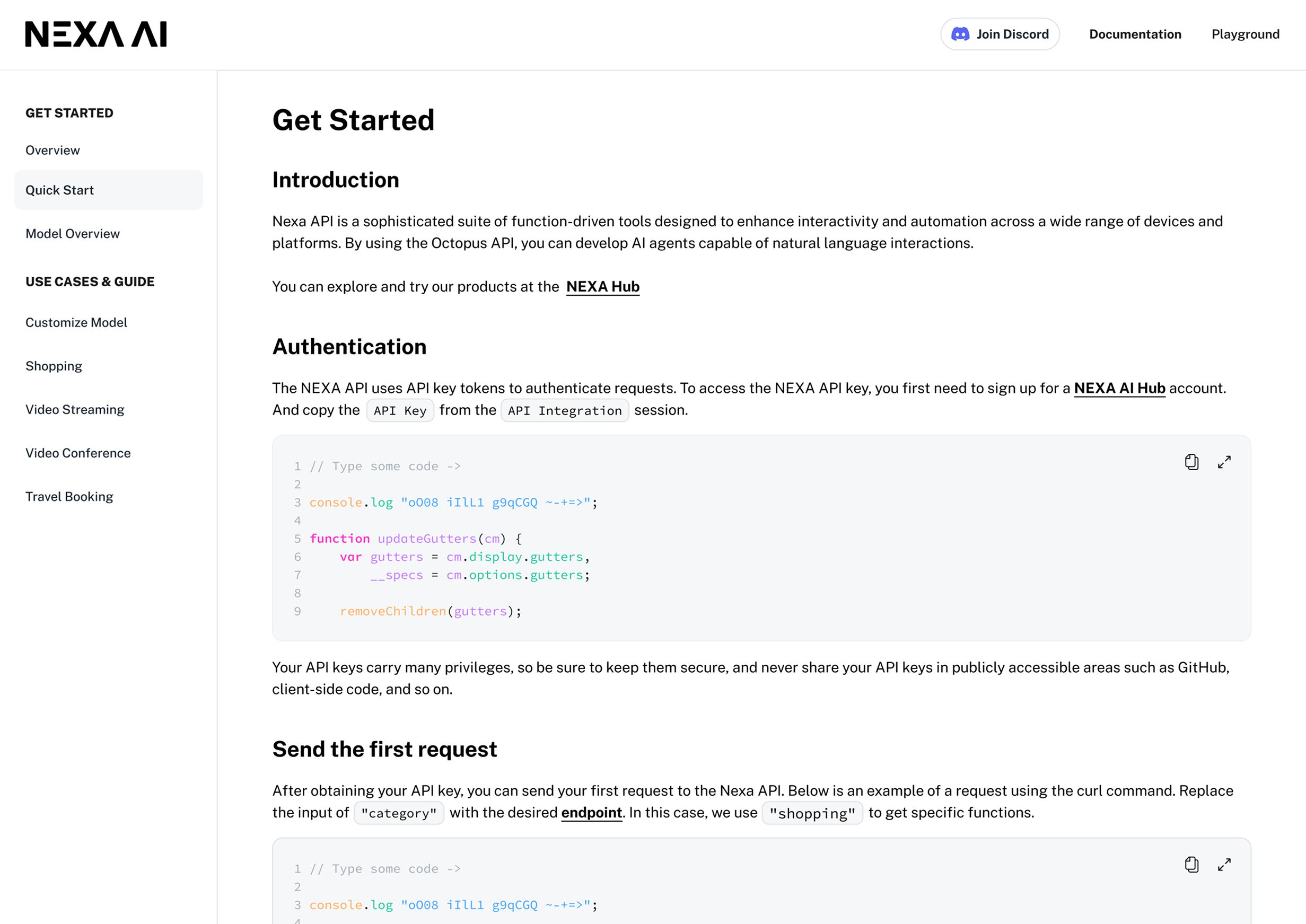
For engineers, the marketing page is the wrong surface. We added a full documentation layer and rewrote the playground logic so model selection, parameters, and execution mirrored the mental model they already use.
Two reading modes on one surface: a scannable Quick Start so a developer is running the model within minutes, and a deeper reference for the ongoing integration work that follows.
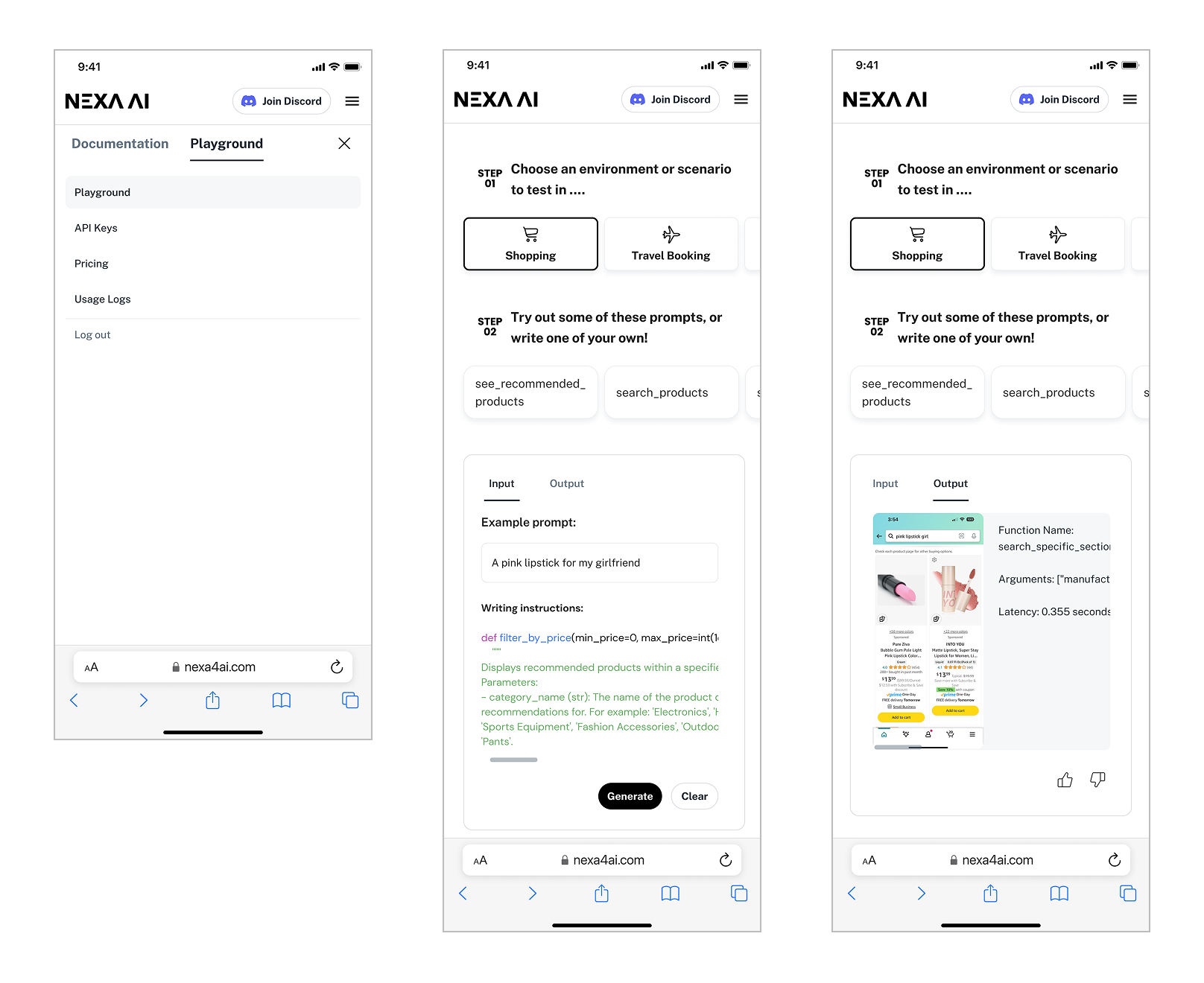
Edge AI's whole point is that the model runs anywhere. The product surface had to match — so the Playground, landing page, and docs were designed responsively from the start, not retrofitted later.
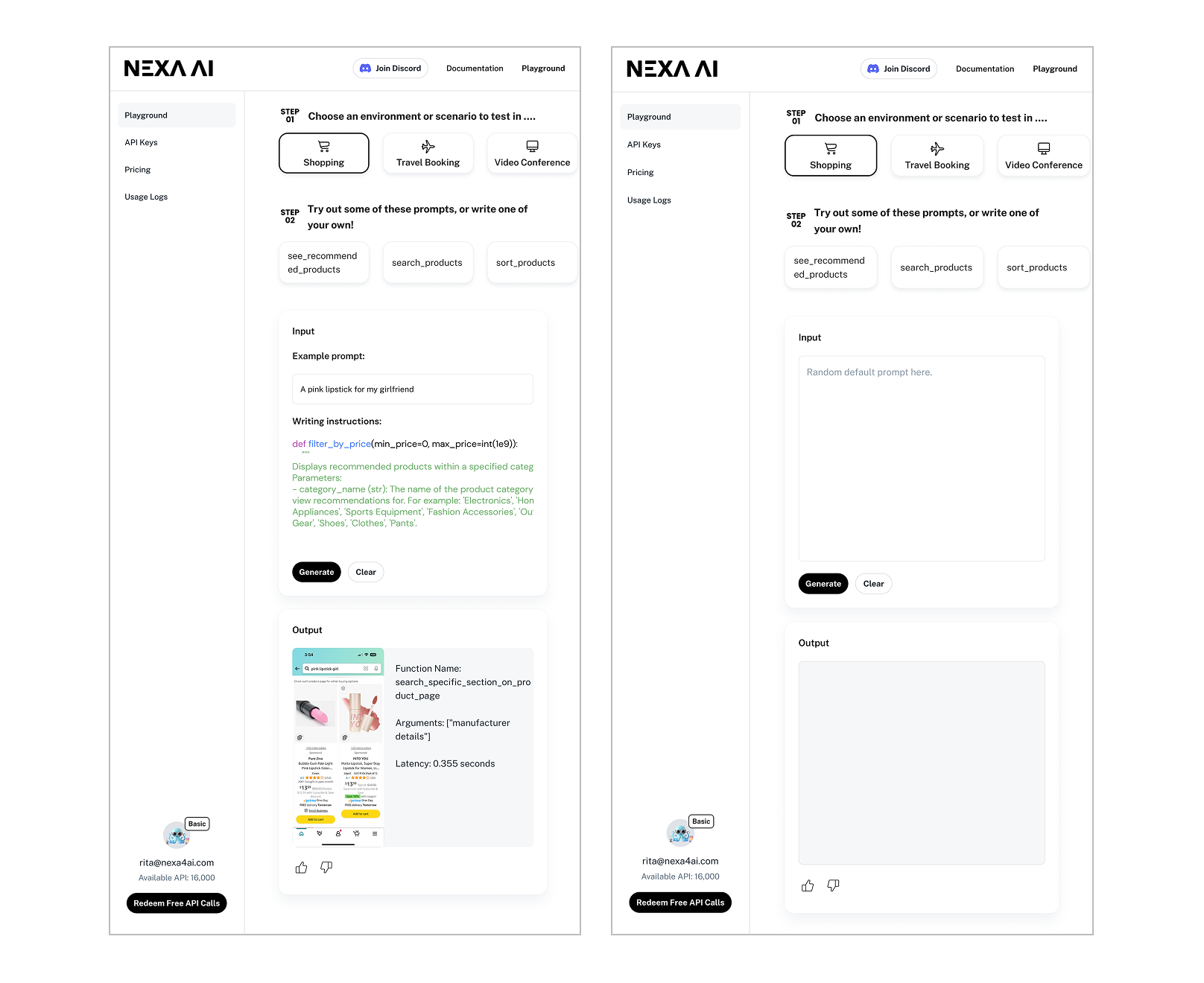
Results
The iteration validated the bet. We hit #1 Product of the Day on Product Hunt, crossed 10,000 API calls in the first month, and the clarity layer — videos, documentation, the Playground itself — became part of the investor story behind our $10M seed close.
Launch
#1
First-day ranking
Adoption
10K+
Month one
Funding
$10M
Closed
Reflections
A lesson I've kept seeing in early-stage work: shipping less, but legibly, beats shipping more that no one understands. By designing for how users actually evaluate new models — by trying them — we reduced friction, aligned the team fast, and shipped a meaningful MVP under a two-week clock. The product wasn't finished. It was understandable. That was enough.